AIモデル小型化技術とデバイス実装

こんにちは、ミラクシアエッジテクノロジーの松本です。
AI技術の発展に伴い、様々な場面でAIが活用される時代となりました。 クラウドでは比較的大規模なAIモデルを運用することが可能ですが、資源が限られているデバイス上では運用できるAIモデルも限られます。
そこで、AIモデルの精度維持とモデルサイズを削減する「モデル圧縮技術」は、デバイス上でAIを運用する製品にとって非常に重要な技術です。
本記事では、モデル圧縮技術の基礎と、物体検知モデルをデバイスへデプロイした事例を紹介します。
モデル圧縮技術の基礎
モデル圧縮技術には主要な方式として、
- 重みのビット幅を削減する「量子化」
- 重要度の低い重みを削減する「枝刈り」
- 大きなモデルの振る舞いを小さなモデルに移す「知識蒸留」
の3種類があります。 それぞれについて、以下で詳しく説明します。
量子化
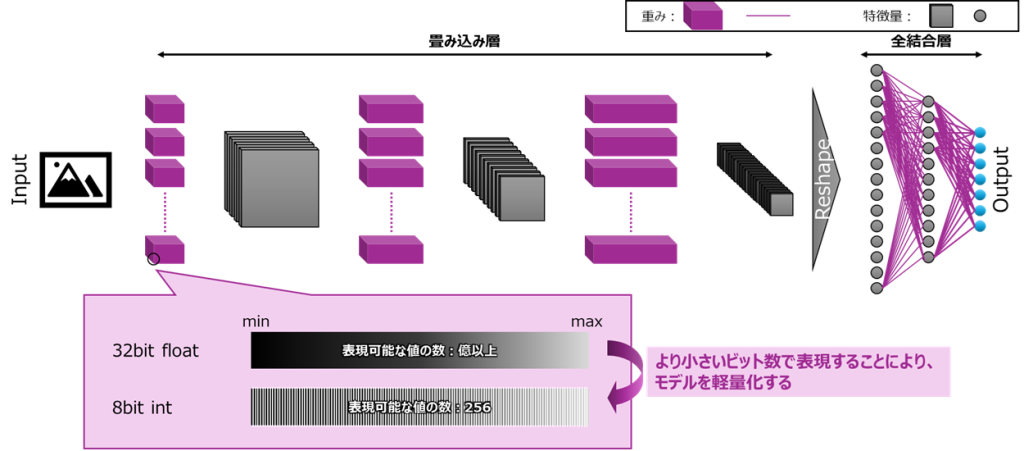
量子化は、ネットワーク内部の数値表現を軽量な整数へ写像して、メモリと処理量を減らす方法です。重みを32ビット浮動小数点から8ビット整数へ変換すると、推論のレイテンシや電力を削減できます。適切に適用すれば、物体検出のようなタスクでも精度劣化を小さく抑えられることが多いです。
具体的なビット数変換はスケールとゼロ点で整数への写像です。重みはチャネルごとのスケールを持つper-channel量子化が主流です。Activationはレイヤ単位のper-tensorが一般的ですが、重みの量子化と異なり、Activationの量子化はデプロイ対象のデバイスが対応していない場合もあり、確認が必要です。表現は重みが対称量子化、Activationが非対称量子化になることが通例です。
量子化には、事前学習済みモデルを量子化するPTQと、量子化を考慮して再学習するQATがあります。PTQは手軽ですが、精度劣化が大きい場合があります。QATは精度維持に優れますが、再学習のコストがかかります。検出タスクでは、PTQで大きく劣化する場合に短期QATで回復を図るケースが多いです。
量子化によるモデル圧縮を行う際は、感度の高い層には注意が必要です。例えば、MobileNetシリーズで使われるDepthwise Separable Convolutionでは、通常のConvolution層を、Depthwise ConvolutionとPointwise Convolutionに分割し全体の計算量を減らす手法ですが、モデル構造上はレイヤが増える形となり、量子化による演算誤差の影響を受けやすい(感度が高い)性質があります。
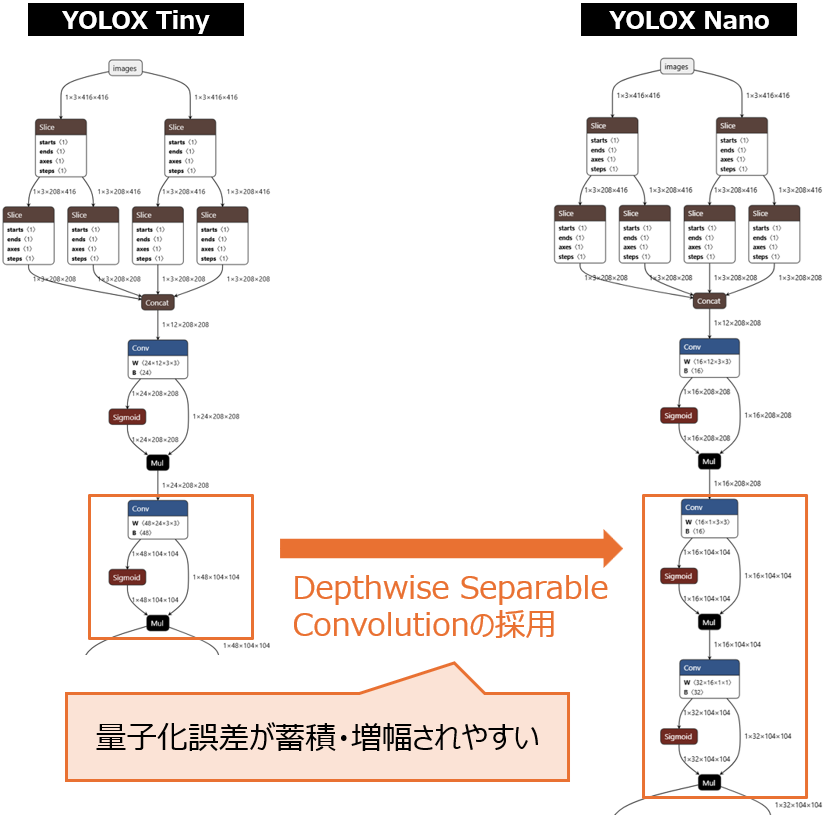
このような感度の高い層に対応する為には、重みはper-channel対称量子化を確実に有効化し、ActivationはPTQではクリップを厳しめに、QATではPACT併用を検討します。どうしても厳しい場合は「DepthwiseのみFP16や高ビットに残し、前後の1×1をINT8にする」といった混在精度のフォールバックが選択肢になります。ただし、TFLiteやNNAPIではレイヤ単位の混在精度を許容しない構成が一般的で、フルINT8でないとDelegateが外れてCPUフォールバックや再量子化が発生しやすい点に注意が必要です。
枝刈り
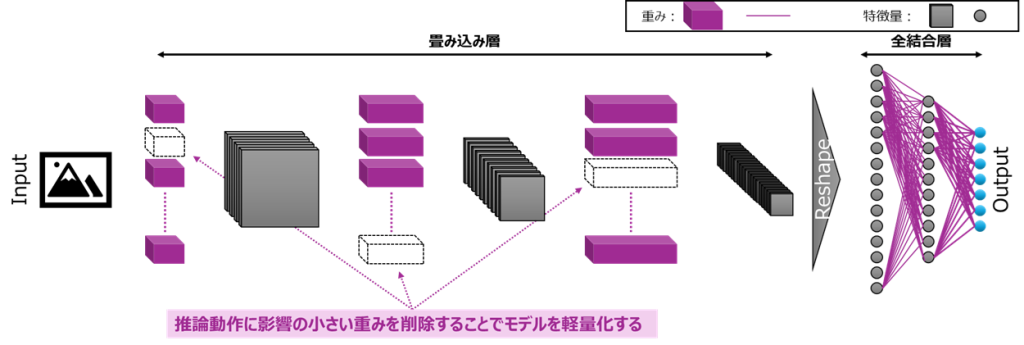
枝刈りは、重要度の低い部分を削ってモデルを軽くする方法です。非構造化枝刈りは個々の重みをゼロ化して疎行列にしますが、実行速度の向上は限定的になりがちです。構造化枝刈りはチャネル、フィルタ、ブロック単位で削り、ネットワークの幅が実際に細くなるため、レイテンシ改善に直結しやすい手法です。
モデル圧縮とレイテンシ改善の両立のために、構造化枝刈りが基本です。チャネルやフィルタを小刻みに削り、短い再学習で回復するサイクルを数ラウンド繰り返します。例えば、YOLOアーキテクチャにおいては、CSP、Concat、Residualでは左右ブランチのチャネル整合が崩れると破綻しやすいため、ブロック単位で揃えて削る方針が安全です。ヘッド側の削りすぎは再現率低下に直結するため、バックボーン優先で進めます。
知識蒸留
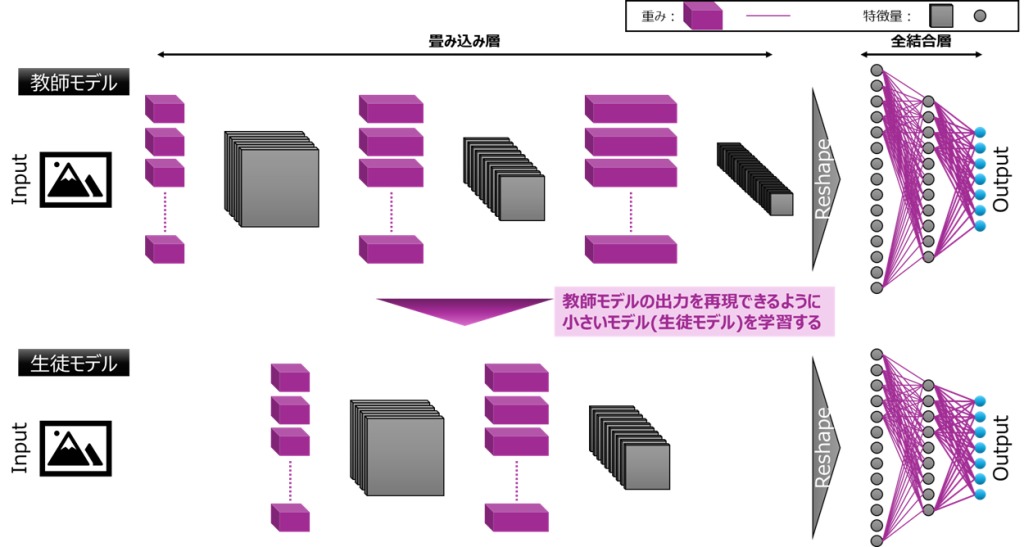
知識蒸留は、大きな教師モデルの振る舞いを小さな生徒モデルに移す学習です。出力確率に加え、中間特徴や位置合わせの手がかりを生徒に学ばせることで、小型でも高精度なモデルを目指します。
温度はおおむね3前後、分類損失、カルバック・ライブラーダイバージェンス、特徴蒸留、局所化蒸留の重みは1:1:1:1から開始し、回帰寄りのタスクでは局所化の比重を高めます。アンカーありとアンカーフリーでラベル割当てが不一致になると学習が不安定化します。入力解像度と前処理を一致させ、教師と生徒のヘッド構造が大きく異なる場合は共通階層に蒸留を集中し、特徴蒸留の比重を上げると安定感が増します。
物体検知モデルのデバイス組込み事例
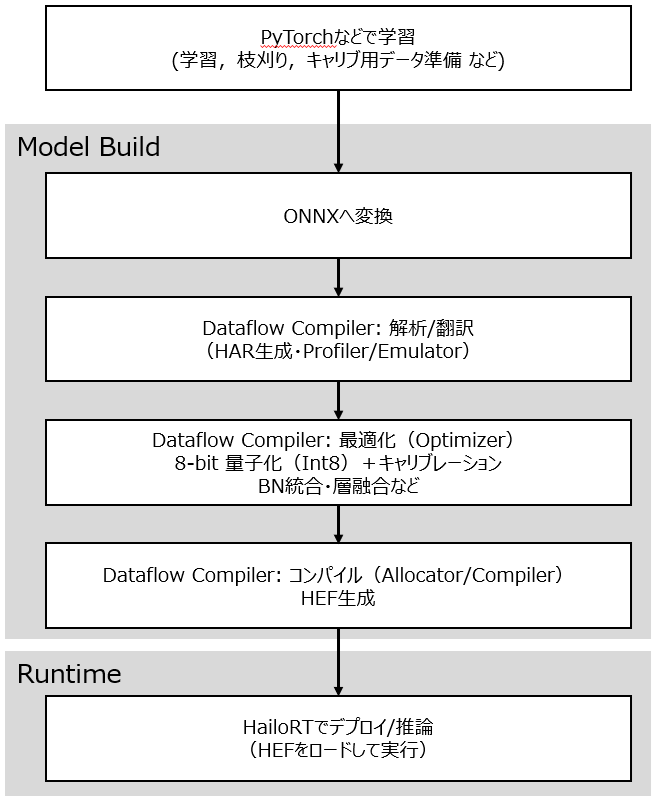
本記事では、YOLOX TinyとYOLOX NanoをHailo8デバイス上に実装・評価した取組み事例を紹介します。 Hailo8のSDKでは、INT8量子化が組込まれているため、モデル圧縮手法として枝刈りを採用しました。
Hailo8とYOLOX Nanoの相性と取組み目標
YOLOX NanoはYOLOXシリーズで最も軽量なアーキテクチャです。 内部構造としては、YOLOX Tinyに対して、
- 各レイヤのチャネルの削減
- Depthwize Convolutionの採用
により、重みのサイズと計算量を削減している点が特徴です。
しかし、量子化の節でも述べたように、Depthwize Convolutionは重みの量子化に対する感度が高い性質を持つ点から、本取り組みでは、YOLOX Tinyを枝刈りによって小型化し、YOLOX Nanoと同等精度のモデルをHailo8上で実行できることを目標とします。
評価条件
| 項目 | 内容 |
|---|---|
| 対象モデル | YOLOX Tiny, YOLOX Nano |
| データセット | COCO2017 |
| 小型化技術 | 枝刈り (パラメータチューニングあり) |
評価結果
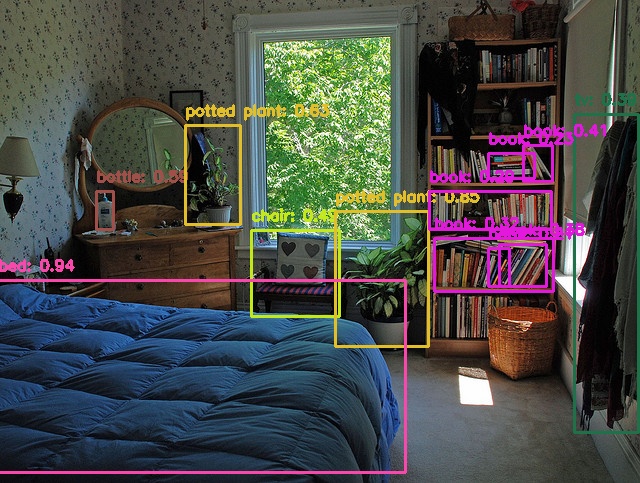
下表に示す通りYOLOX Nano (Official)はPC上ではmAP=25.8だったものが、Hailo8デバイス上ではmAP=0.00と、正しく推論が出来ていないことが分かります。検出例でも、Hailo8デバイス上では、bananaと推論される物体が多い点からも正しい推論が出来ていないことが見て取れます。Hailoデバイスではモデルをデプロイする際に、Dataflow CompilerにてInt8量子化が行われますが、この量子化の影響が生じているものと考えられます。
一方、YOLOX Tiny (枝刈り後)はPC上ではmAP=28.2だったものが、Hailo8デバイス上ではmAP=20.4と、やや精度低下が生じたものの、YOLOX Nanoと比較すると高い精度を保てています。検出例を見ても、bananaと推論されるオブジェクトは存在せず、物体検出が機能していることが見て取れます。
| モデル | 評価環境 | Param数 | 重みサイズ [MB] | mAP(0.5:0.95) | 検出例 |
|---|---|---|---|---|---|
| YOLOX Nano (Official) | PC | 910,000 | 7.33 | 25.8 |





|
| YOLOX Nano (Official) | Hailo8 | 910,000 | 7.33 | 0.000 |





|
| YOLOX Tiny (Official) | PC | 5,060,000 | 39.81 | 32.8 |


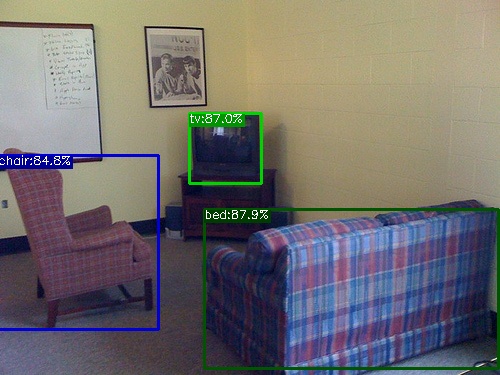


|
| YOLOX Tiny (枝刈り後) | PC | 695,000 | 5.56 | 28.2 |





|
| YOLOX Tiny (枝刈り後) | Hailo8 | 695,000 | 5.56 | 20.4 |
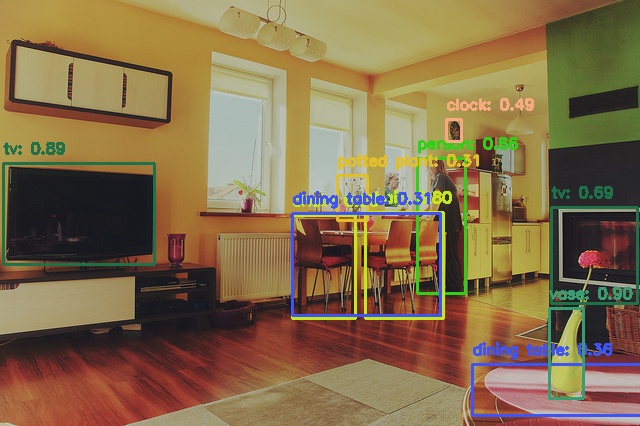



|
まとめ
本記事では、モデル圧縮技術の概要と、ミラクシアでのデバイス組込み事例を紹介しました。 YOLOX NanoはYOLOX Tinyを更に小型化したモデルですが、Hailo8デバイスに対してはYOLOX TinyをDepthwise Separable Convolutionで小型化するよりも、枝刈りで小型化する方が相性が良い結果でした。
AIモデルの小型化技術を用いることで、所望のAIモデルをデバイスに組込むことができるようになります。 しかし、デバイスが持つ演算器やデバイスごとの開発環境に応じて、採用できるモデル圧縮手法が異なります。 モデルやデバイスに応じて適切な方式を採用することが重要です。
ミラクシアでは、モデル圧縮技術以外にも、デバイスに合わせた実装技術やデータ分析技術など、エッジAI開発における主要工程の技術を保有しています。 デバイスへのAI実装について、お困りごとや関心などがございましたら、お気軽に相談ください。
採用情報
ミラクシアでは一緒に組込みソフト開発をする仲間を募集しています。